RabbitMQ Partial Order Implementation using Consistent Hash Exchange. Golang.
This article is an extended version of my presentation about RabbitMQ to my coworkers. I’m publishing it just for fun.
I’ll cover basic RabbitMQ concepts. We will implement Producer/Consumer POC with reconnecting and graceful shutdown. You’ll learn how to implement preserving partial message order using rabbitmq_consistent_hash_exchange plugin.
As a bonus, you’ll see an example of how to use Nomad for local development environment management and Mage as a makefile alternative.
For a link to the source code scroll to the bottom of the article.
Messaging and queues in general
Today, any system that is a little more than just a TODO list app, cannot live without messaging system. There are many reasons to introduce queues in your system. Let’s go through the most popular:
- Reliability
- Resiliency
- Scaling
- Asynchronous communication
- Delayed/long-running jobs
- Decoupling
- Load Control
- Etc.
Reliability
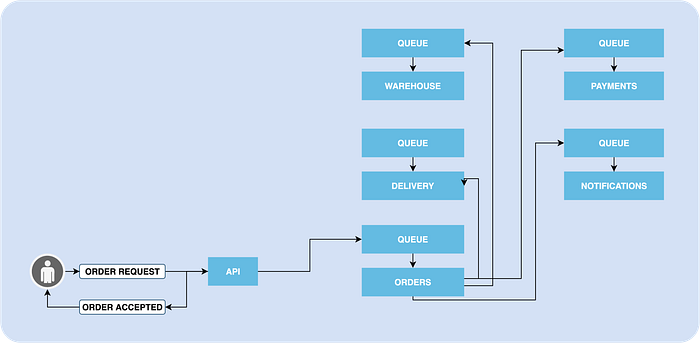
Imagine an API, which is receiving orders of some products. Ordering a product is not a simple operation. It can include checking the warehouse to see if the product is still in the stock, payment processing, initiating delivery, sending emails and etc. Naturally, multiple databases and even 3rd party services will be involved in this “simple” flow.
What will happen when a customer tries to submit the order, but the delivery service has a bug? What will your API do if your warehouse service has temporary network issues and cannot connect the database? There can be many reasons to fail and miss the order.

The queue will allow you to receive the order, which is a relatively small piece of information, and keep it until you finish the processing. Once you receive the order as a message, you can process it, store it, schedule retries, or even send it to another queue. The main idea is that you can process it later, and give yourself a chance to successfully finish the business flow.
Resiliency
This one is directly related to the concept of reliability. To be resilient, you must be reliable first. Once you have a message in the queue, you know that if some service is not available right now, you can always try later. You can apply different strategies for processing the message.

For example, if the warehouse service was down for an hour, imagine how many orders you can lose because you cannot check if the product is still in stock.
But, as soon as the warehouse service becomes available again, you can process the orders, and in case of missing product, send an email to the customer. The customer will not even know about any issues on your side.
Scaling
Think about API service like lightweight endpoints which do validations and send messages. those operations are very fast. You can send thousands of messages in a second to the queue.
You can process the messages at the needed rate by adding new consumers. As a side effect, you have fewer chances to be down as a result of a Denial of service attack, cause the endpoints are very fast and finish the job quickly.
Additionally, your internal services are also protected, cause you can throttle the message processing to keep the load under control and drop “bad” messages in realtime.
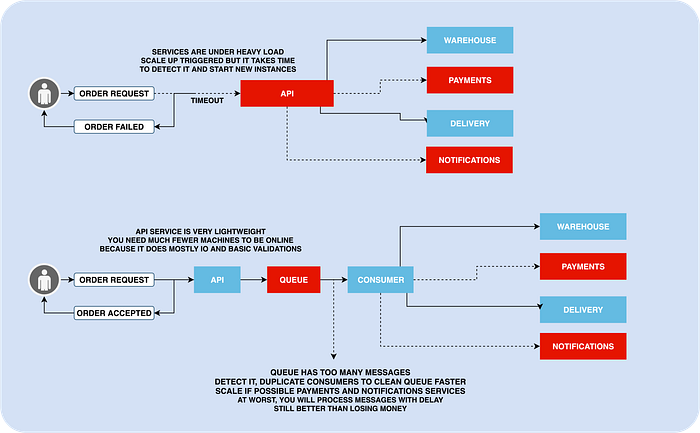
The simplest implementation of consumer's auto-scaling can be based on the number of messages or/and waiting time metrics.
Asynchronous communication
Imagine you are ordering pizza, and you need to be on the phone until the delivery guy will come to your apartment? Sounds weird…
The customer doesn’t need to wait until we finish processing his request. We can just say him that we received the request and notify him by email when we are done.
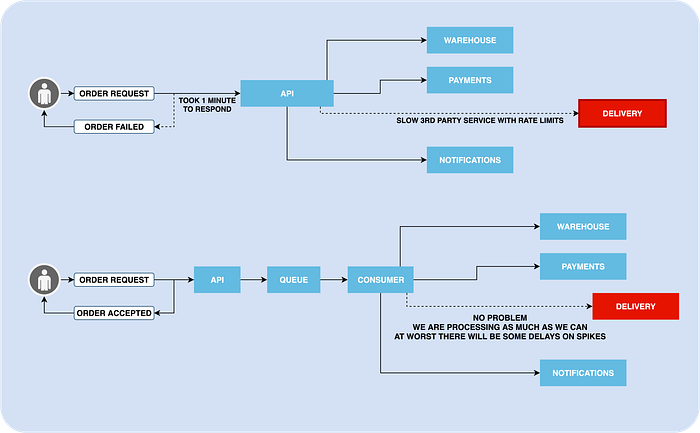
From the architectural point of view, asynchronous communication is a core in Event-Driven Design. You can put queues for each internal service, and allow communication only by messages. But it too much to draw ;) and that by itself is a very broad topic.
Delayed/long-running jobs
Queues often used as a solution for delayed and long-running job processing.
Tasks like image processing, report generation, loading pricing lists as big CSV files often slow should be done asynchronously.

Many queues support delaying the messages out of the box. For example, you can schedule a notification with a discount to be sent 10 days after receiving the first order from the customer.
Decoupling
By introducing a queue in the system, you are actually decoupling the part of the system that creates messages from the part of the system that consumes messages.
It means you can implement, change and maintain these sides of the system separately. You can use different technology stacks. You can have different teams with separate ownerships.
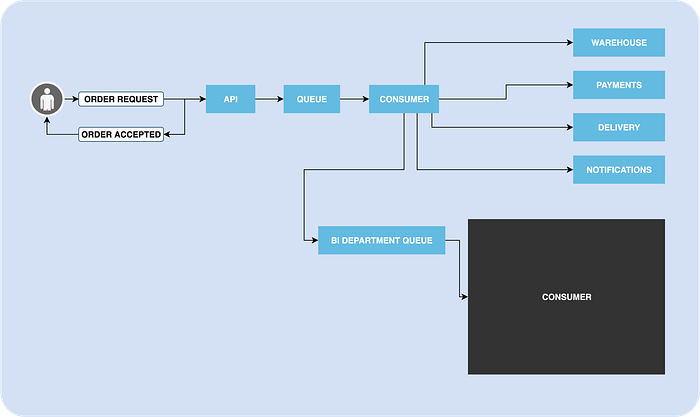
BI team can listen for the message sent by your system, and do their own processing. The team that is responsible for throwing this message should not worry about the stuff the BI team is doing. It kind of a black box. You only should agree on the schema of the message.
Load Control
The queue can be used to control the load and provide predictable behavior.
When you will receive a huge amount of order requests, you can implement the workers to consume messages at a predefined rate. By doing that you can prevent abusing databases or even other services.
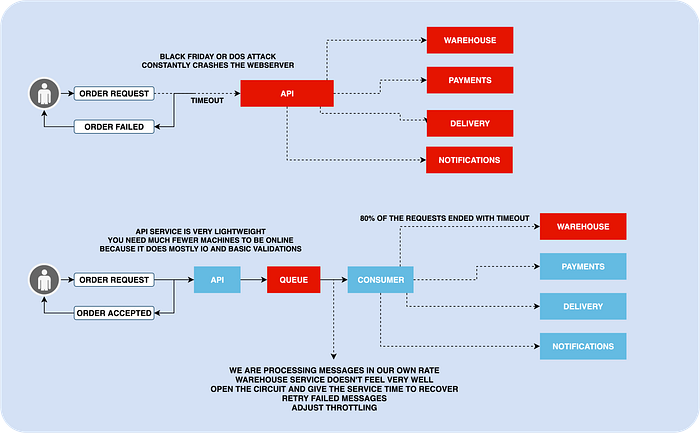
When other services respond with too many errors (we are assuming consumer talks with other services synchronously via HTTP/GRPC/GRAPHQ), you can stop abusing them by implementing the Circuit Breaker Pattern.
Summary on queues
Which data can be sent to the queues? It can be analytics data that are streamed in real-time directly from the websites, data received from IoT or mobile devices, business events, and many more.
In an ideal world, web servers are very small and simple blocks of the system that’s only queries needed data from an optimized data storage. All the “processing” is done in an asynchronous way by workers that receive the messages, and do not affect the web server's performance.
Once you are starting to dive deeper into the messaging it opens to you a whole new world of concepts like Producer-Consumer, Event-driven architecture (EDA), Event stream processing (ESP), Domain-Driven Design (DDD), Event Sourcing, which cannot be covered in this short introduction.
But don’t get me wrong. Messaging solves many issues and has many advantages, but as always, you get nothing for free. This is a different way of thinking and building of the systems with their own pitfalls, issues, solutions, architecture, anti-patterns, and best practices.
What is RabbitMQ?
RabbitMQ is one of the most popular open-source message brokers. Think about it like a very smart buffer, that sits between sender (producer) and receiver (consumer), and knows to deliver messages from the producers to consumers according to some rules, and decoupling your system as a side effect.
It’s distributed, reliable, and mature product, with a single killer feature — routing. RabbitMQ supports very flexible routing, that allows you to build complex system using simple routing rules. You don't need to deal with it manually by inventing the wheel, because RabbitMQ can do it fast, and with minimal effort from you as a developer.
Here I’ll refer to the features, of the RabbitMQ in the context of AMQP 0–9–1
Basic RabbitMQ concepts
RabbitMQ has 3 main concepts: exchanges, queues, and bindings.
Exchanges
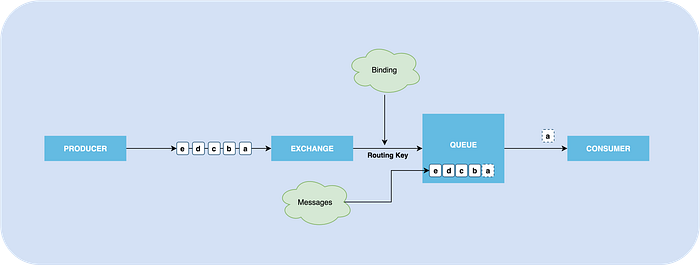
In RabbitMQ, messages are not published directly to the queue. Instead, producers send messages to exchange and know nothing about the queues and consumers.
Exchanges are responsible for routing the messages to queues (or other exchanges) according to specific rules which strongly linked to the exchange type, which will be covered later.
Multiple producers can send messages to the same exchange. Multiple queues and exchanges can be bound to the same exchange.

Queues
Consumers, in differ from producers, read messages from specific queues. The consumer initializes a TCP connection to the RabbitMQ, opens the channel (logical connection to the queue) to the queue, and starts receiving the messages. By using multiple consumers on the same queue, our system can scale.
Do you have 1 million messages to process? Not a problem. Create 100 consumers, subscribe to the queue, and 1 million messages will be distributed to these consumers.
Each message will be delivered at least once to each consumer. Important to understand — each consumer will receive a different message!
Note: RabbitMQ uses a push mechanism (opposite to polling) to propagate messages to the producer.
The queue can be bound to multiple exchanges, which allows you to create complex system topologies to satisfy many business requirements.
You can subscribe to multiple queues using the same single TCP connection, by utilizing the multiplexing feature of channels.
Bindings
How does the exchange know where it should send the message? This is where bindings do their job. Bindings are virtual connections between exchanges and queues or other exchanges.
RabbitMQ has multiple exchange types, where each of them uses different binding semantics. For example, rabbitmq_consistent_hash_exchange treats binding routing key value as a priority, where the direct exchange will actually compare its value against the routing key on the message.
Additionally, binding supports custom arguments that add even more flexibility.
Basic RabbitMQ Exchange Types
Fanout Exchange
This type of exchange is the dumbest and fastest exchange RabbitMQ provides us. A fanout exchange just copies and routes a received message to all queues that are bound to it regardless of routing keys.
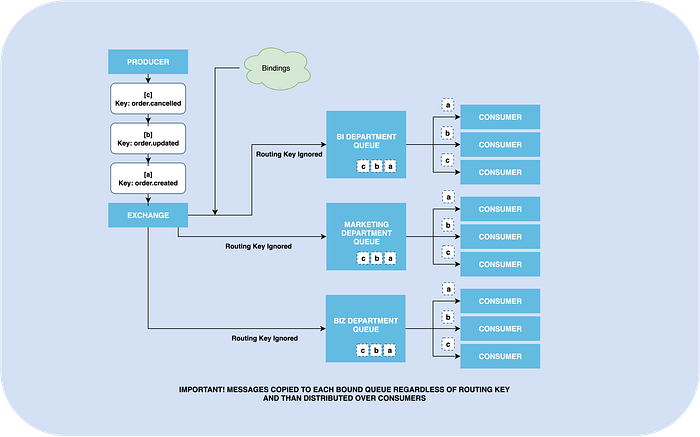
It can be useful in cases when multiple stakeholders interested in receiving the same messages regardless of their routing keys. For example, you can send the same messages to different departments, and they will do their own business.
Direct Exchange
This exchange delivers messages to queues by comparing provided routing key with existing bindings. If multiple queues bound with the same key, messages with this routing key will be copied to all of them.
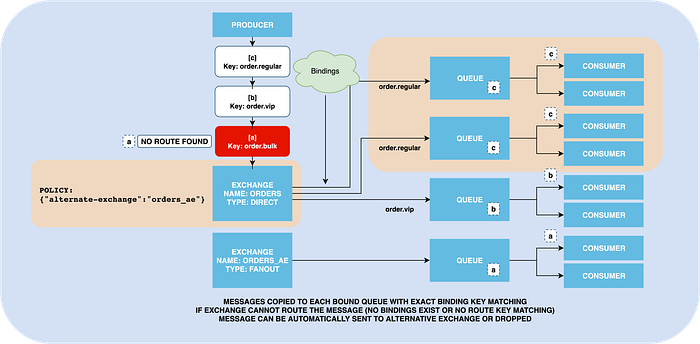
In case the exchange cannot find where to route the message, the message will be dropped.
If you want to prevent it, you can create an alternate exchange with fanout type, and attach it to the exchange. Any unroutable will be sent there be sent to this exchange.
Of course, to not lose them in the alternative exchange you need to attach a queue to it.
This feature can be used for detecting when someone is sending messages with the wrong route key. Or, you can treat the alternate exchange as the default behavior for all routing keys, and route only specific messages to other queues.
Topic Exchange
Topic exchanges are similar to direct exchange but much smarter and flexible. The idea is that you can define a kind of “regex” matcher as opposite to equal direct exchange that only knows compare for equality.
The routing key should have a specific format. It must be a list of words, delimited by a period (.).
The routing pattern can use * or # to match single and zero or more words.
For example, topic exchange with pattern *.order.* will route messages with routing keys:
eu.order.regularusa.order.vip
But not:
eu.order..order.vipusa.order.vip.helloorder.vip.hello.world
By changing it to #.order.# all the cases will be matched.

Basically, you can use the topic exchange to emulate Direct and Fanour exchange behavior.
Just take to account, that even the RabbitMQ itself is pretty fast, pattern matching considered a slower operation than exact equality checking (direct exchange) or routing without even checking the routing key at all (fanout exchange).
But with the flexibility it provides, you can create really cool routings.
Header Exchange
A headers exchange routes messages based on the values in the headers that can be assigned to each message before publishing. It’s a kind of topic exchange on steroids.
A message matches if the value of the header equals the value specified upon binding. A special meaning argument x-match added in the binding defines if the rabbit should check all the headers before routing or just one match is enough. It must have value either all or any, where the last means at least one.
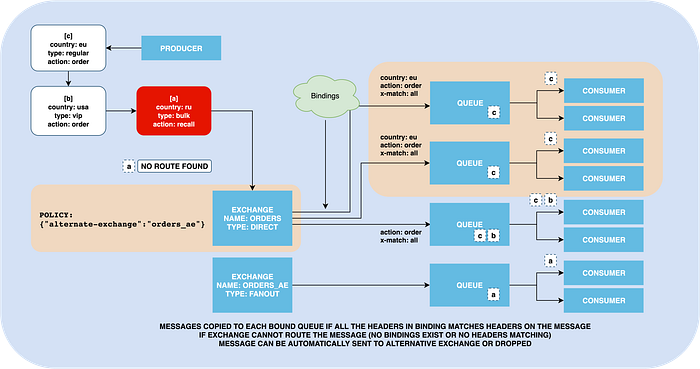
This exchange ignores the message’s routing key value, and does routing only by evaluating headers.
Message Ordering
When we are talking about message ordering, we basically imply two types of ordering.
- Global ordering
- Partial ordering
By definition, an abstract queue is a FIFO data structure. But, things become a little bit complicated when we are talking about distributed systems like RabbitMQ. You know, all this lies about reliable network…
Luckily, the AMPQP 0–9–1 protocol implemented by RabbitMQ provides us these guarantees:
Messages published in one channel, passing through one exchange and one queue and one outgoing channel will be received in the same order that they were sent.
Let’s assume we are working on a multitenant application, with a big enough amount of customers and traffic.
Multi-tenant applications allow you to serve multiple customers with one install of the application.
Most of the web applications are multi-tenant. They are built as a single solution that provides a set of flows to all its users but knows to separate the data, for example by customer id.
Now imagine all the messages from all the customers sent to a single queue.
- ProductAdded
- ProductTitleChangeRequest
- ProductDeleted
- OrderCreated
- OrderUpdated
- OrderCancelled
- OrderDeleted
All these messages will be received by a consumer in their original order. Let’s refer to it as Global Ordering.
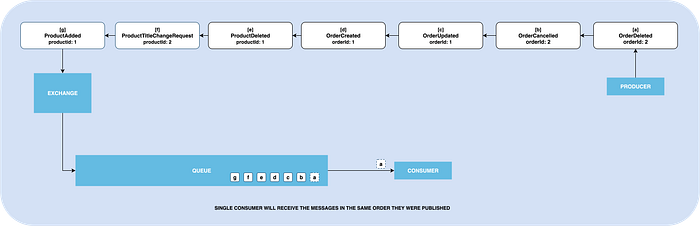
But there are a few issues here. When you have thousands or millions of messages for different products and orders in the queue to be processed, it will take a while. Some flow cannot accept such behaviors. Most times we want to keep the queue empty and process the messages as fast as possible.
What is the solution? You are right, we already talked about it. Scaling!
Let’s just create multiple consumers and subscribe them to this single queue. So far so good. We are able to process all these messages very fast. But, we loosed Message Ordering.
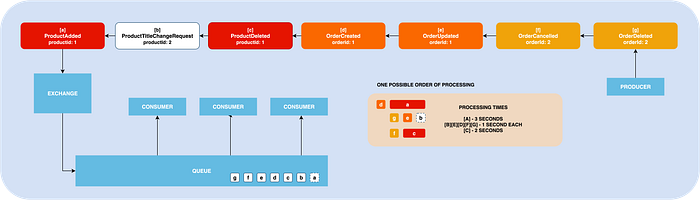
Now messages will be distributed over all the consumers using a round-robin algorithm. Asap as some consumers finished message processing, RabbitMQ will send the next message to it.
But, you don’t really know which order it will be processed. It depends on the message processing time. Sometimes the order will be completely reversed.
Honestly, the out-of-the-order message issue itself is not hard to solve. Any good messaging system should be developed to be independent of the message order.
The real issue is the parallel/concurrent processing. Sometimes messages will be started almost simultaneously, and who knows what will the result of it (message [c] processing on the screenshot starts with [a] but finishes earlier).
You can use transactions if you are working with a database, but the hardest Serialisable Isolation will hit the performance, and many databases don’t support this level of isolation.
Optimistic concurrency, locks, or other solutions can help to minimize the damage, but it will not solve all the problems, will affect performance, and introduce new bugs.
Life with such a system soon becomes a nightmare.
Partial Ordering over Global Ordering
So, what can we do?
Firsteful, in most cases, you don’t need Global Ordering. You don’t care about the order of ProductTitleChangeRequest and ProductDeleted messages of different products. They can be processed in parallel without any issues in most cases.
What you really need, it’s that messages related to the same item will be processed in its order. You want ProductTitleChangeRequest and ProductDeleted messages for the same product to be processed in the order they were published. This is what we call Partial ordering.
To achieve this behavior, we need to promise that the message for the same item will be received by the same consumer.
And guess what? When you will implement it this way, you can easily deal with issues like out-of-the-order messages. If you get OrderCancelled message, but the order doesn’t exist, you can handle it by creating a dummy order with some flags, and then when OrderCreated message will arrive, handle this situation. You can do it safely cause you know nobody will try to do the same in parallel.
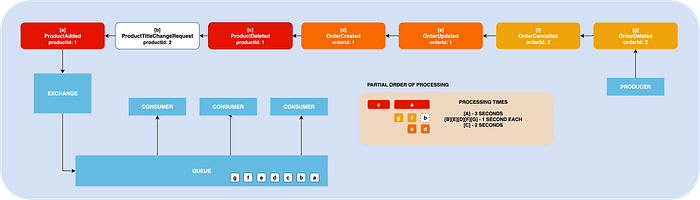
RabbitMQ Consistent Hash Exchange Type to rescue
RabbitMQ has a built-in plugin, named rabbitmq_consistent_hash_exchange, which can be used to achieve our goal. In simple words, this plugin knows to apply some smart hash function to the provided routing key or special header value, and route the message to the same queue.
Using the header’s value for hashing is more flexible. This way routing key can be used for routing when multiple exchanges involved.
To ensure Partial Ordering, we still must promise a single consumer per queue. But, now the unit of our scaling is not the consumer, but the queue.
So now, instead of having a single queue, we will create many of them. All queues will be bound to the consistent hash exchange.
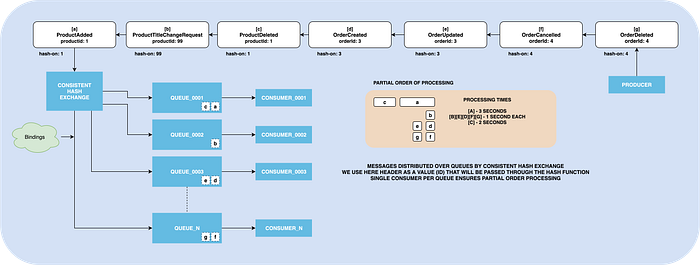
If later you’ll see that your amount of messages increased, and you need to scale more, just add a new queue, bind it to the exchange, and RabbitMQ will automatically rebalance all the messages.
But,…
There is always but…
Whoever is familiar with Kafka, knows that it provides Partial Ordering when a single consumer per partition used. Actually, what we are trying to do here with RabbitMQ, is to emulate the same partitioning behavior provided by Kafka, using queues.
The sad thing is that RabbitMQ doesn’t provide out-of-the-box tool for automatic assignment consumers to the queues.
If using Kafka, you have created 25 partitions, and want to use 5 consumers only, because there is no heavy load on the system right now, Kafka will automatically assign partitions to these 5 consumers. Adding or removing consumers will trigger automatic reassignment flow.
In our RabbitMQ implementation, we will need to deal with it manually.
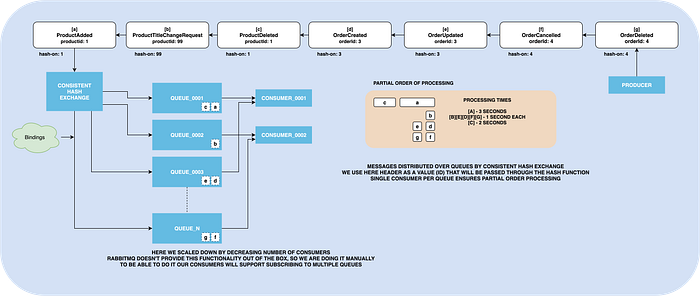
A single attempt to create a semi-automatic tool I found by googling is a Rebalanser project, that is kind of abandoned right now. The good news is that the guy that worked on is working at RqbbitMQ right now, so I’m full of hope someday, we will have this feature built-in at RabbitMQ.
But things are not so bad like they were. We will implement a solution that can fit many cases, with help of the new Single Active Consumer feature of RabbitMQ that simplifies many things.
RabbitMQ Single Active Consumer feature
As said in the documentation, a single active consumer allows having only one consumer at a time consuming from a queue and to failover to another registered consumer in case the active one is canceled or died.
It means we don’t need to implement stuff to ensure we have only a single live consumer for a specific queue and implement magic to synchronize consumers to decrease downtime. It simplifies things a lot.
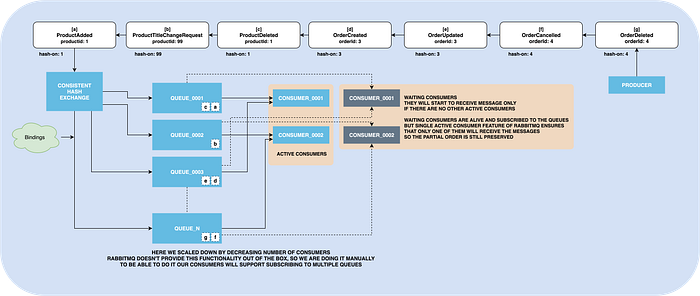
This feature is available from RabbitMQ 3.8
Solution
We will implement a consumer, with multiple queues connection support.
Whenever we want to scale up/down, we will generate a new queue-to-consumer mapping file, stop all the consumer instances and start again with new mapping. And the trick here is that we don’t really need to wait for the old instances to die, we will start new instances asap.
If the old instances will be already dead when new instances started, we are good. The new instances will start consuming the messages. If the old instances will be still alive, as part of the graceful shutdown, it's even better, because when they will die, the new instance will start consuming messages immediately, without any downtime.
Project high-level overview
To emulate deployments locally we will use Nomad.
A simple and flexible workload orchestrator to deploy and manage containers and non-containerized applications across on-prem and clouds at scale.
You can think about Nomad as powerful but easy-to-use Kubernetes. It has good documentation, a friendly community, and being actively developed.
Project Structure
The project will consist of multiple executables:
- Manager — cli
- Producer — will generate dummy data and publish messages to exchange
- Consumer — will subscribe to at least one queue and process messages
- Abstraction over RabbitMQ driver
We will implement
- Creating exchanges/queue/bindings
- Producer with auto-reconnect
- Consumer with multiple queues subscribing
- Gracefull shutdown
- Manager — cli
Test dataset
I’ll use a free dataset in the producer with thousands of messages for testing our POC.

Enough with the theory!
I’ll not show all the source code here. Just important stuff. You can find the link to the full source code at the bottom.
Topology
Our POC will support architecture, where multiple teams are interested in the same messages and want to preserve Partial Ordering.
There will be the main fanout exchange that will receive all the messages from the producer(s) and copy them to all the bound exchange (exchange to exchange binding).
The second layer of the exchanges will be set up with a consistent hash type and will route the messaging to the bound queues.
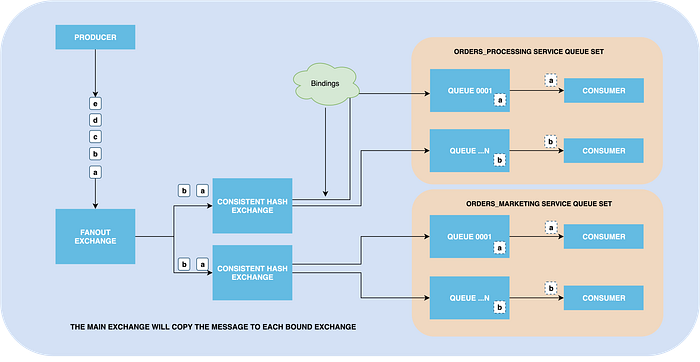
Producer
The producer will connect to RabbitMQ, create the channel, declare the main fanout exchange, initialize listeners for connection errors, and set up tear down.
If a shut-down signal received, tear-down will be triggered. Any try to send the message on stopped producer will end up with the error.
The connection_name parameter is very useful in production when you want to understand who is connected to the RabbitMQ.
All the parameters for declaring exchange will be taken from configs. In our case, the exchange type will be fanout cause we want to copy messages over bound exchanges.
When the useHeader is on, we will use the header’s value instead routing key. This way routing key can be used for routing by other types of exchanges.
Our producer will be able to send messages only to a single exchange for simplicity. In general, you can create many channels on the same connection to be able to send messages to different exchanges over a single TCP connection.
To prevent losing bindings between RabbitMQ restarts we will set them as durable.
When the producer will be started, it will declare exchange and immediately start sending messages. As we didn’t bind any queues to the exchange, messages will be dropped by the exchange. To prevent it, we could create an alternate exchange, and bind a special queue, so unroutable messages would be routed to it.
In our implementation, however, we will want to know if the message was not routed as expected. Also, we want to know about all network errors. All this is done by creating listeners, which will listen for the errors sent to go’s channels.
Before sending the message we check if tear-down was not initialized, and set up some per-message-specific parameters. Our message structure wrapped with an envelope object, which includes an actual message struct that will be serialized to a JSON byte array that will be actually published.
You can see that we put our routing key to the hash-on header, the same header name we declared the exchange.
Here we actually trying to publish the message. If we fail here, it’s probably because of connection issues, so we will try to reconnect and send messages again.
Reconnect is a little bit tricky. The method SendMessage can be used from different goroutines. Publishing itself is a thread-safe. But, if there will be connection errors, multiple goroutines will try to reconnect. We want to be sure we reconnect only once. This is the reason we have reconnectGuard mutex inside the method SendMessage.
Consumer
Consumer, after the connection with RabbitMQ, has been established, will try to declare the same main fanout exchange like the producer does. This operation is idempotent.
Also, consumers will declare “second layer” exchanges within the queues, by conventions and config from the manifest file.
Here we actually creating our topology. Actually, it creates coupling, because the consumer knows about exchanges. To prevent this coupling, there should be someone (DevOps?), who will be responsible to create the topology before we start producer and consumer.
But, for simple topologies, you can create a lib that will set up the topology automatically (like in our POC) and increase the team’s velocity.
Consumer implemented with simple abstraction, so the upper-level code knows nothing about the amount of queues consumer will connect to. This handler emulates long-running message processing and shows how the context can be used to stop the processing in case it was canceled on tear down.
Under the hood, the consumer subscribes to the queues in separate goroutines and calls the provided handler on each received message.
If the handler will return an error, the message will be nacked, otherwise acked.
In a real project, it’s better to handle failers by sending them to other exchange with the different consumers that know what to do with failed messages. Also, you can implement retrying or/and automatically send nacked messages to the dead letter exchange.
RUNNING THE PROJECT
If you want to play with it locally, you need:
- go version go1.14.1 darwin/amd64
- Docker
NOMAD SETUP
Install the Nomad (more in official docs).
brew tap hashicorp/tap
brew install hashicorp/tap/nomadRun nomad in a dev mode, so the raw_exec plugin will be enabled by default. Our consumer will be run using this plugin.
nomad agent-dev -bind 0.0.0.0 -log-level DEBUG -dc localThen, let’s start RabbitMQ instance. This command will download Bitnami RabbitMQ docker image, enable the plugins we need and start it up. We will use a tiny cli I prepared by using Mage.
cd ./gorabbit/infra/cli
go run cli.go SystemUpOpen the http://localhost:4646/ui/jobs URL in the browser. You need to see an empty UI.
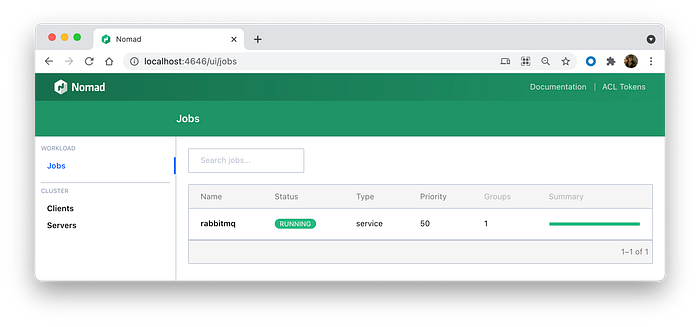
RabbitMQ job should be green. It means we are good and you can visit RabbitMQ UI on http://127.0.0.1:15672/#/
Username: user
Password: bitnami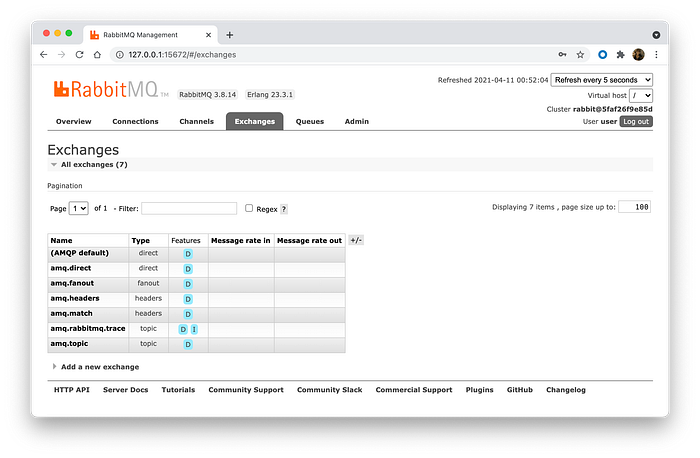
You can see the default exchanges RabbitMQ provides.
Now, let’s run our consumers. Our POC emulates cases where two different teams are interested to receive the same messages and keep partial ordering.
Run the consumers by the command
go run cli.go upIt will run consumers using pre-generated Nomad jobs files
infra/nomad/jobs/orders_marketing.nomad
infra/nomad/jobs/orders_processing.nomadgenerated from the manifest file:
infra/cli/manifest.json
Now you should be able to see our jobs in the Nomad UI. If all is OK, they are green. If not, they will be red and you will need to see the logs tab.
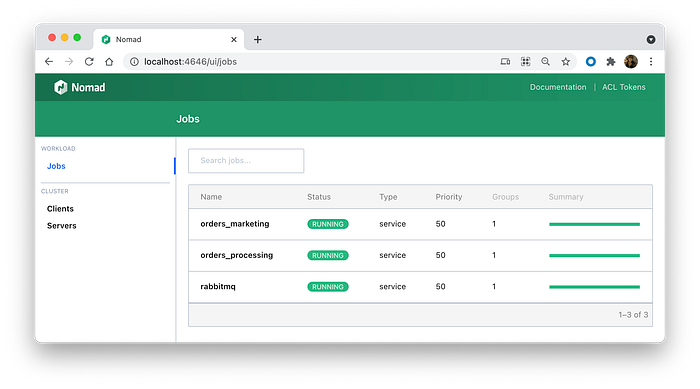
You can click the order_processing job, and you will see that we have 4 running consumer instances. Just like we defined in the manifest file (instancesNumber).
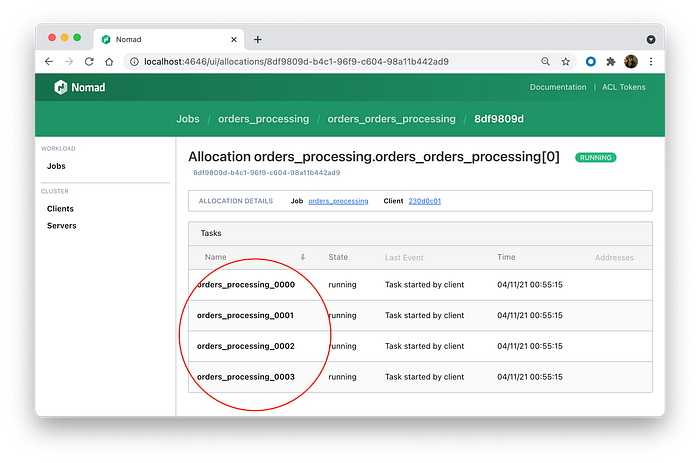
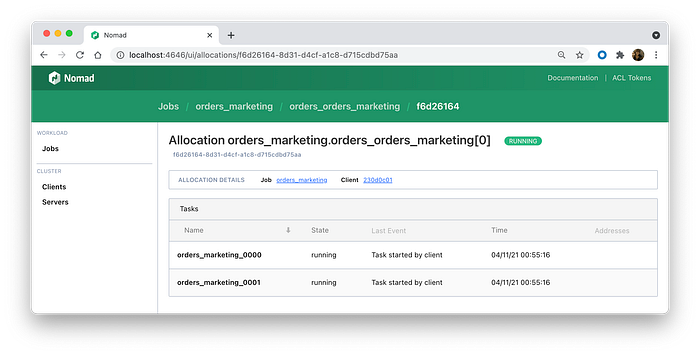
On the other side, you can see that we have only two instances of orders_marketing consumers.
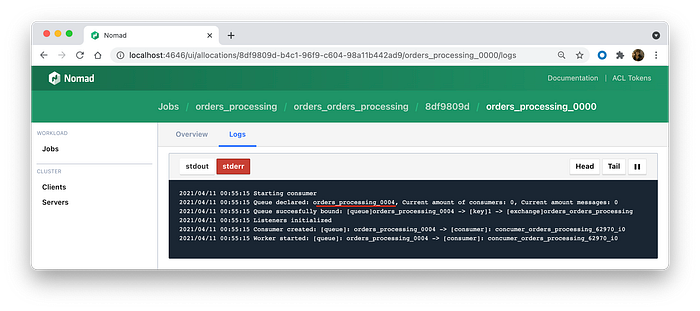
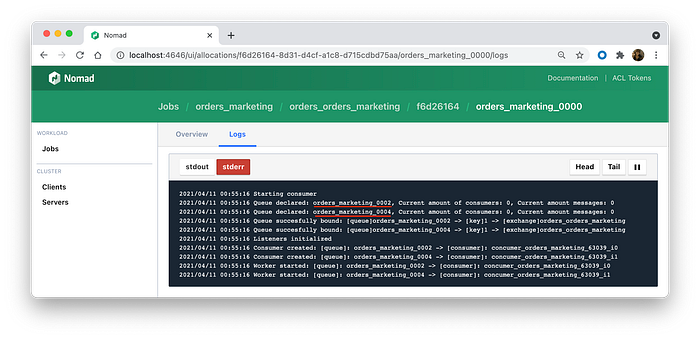
If you look at the logs, you will see that they are successfully declared all the needed exchanges and queues, and just idle.
If you open RabbitMQ UI, you will see 3 exchanges. The main one, orders and two other, orders_processing and orders_marketing .
Exchanges orders_processing and orders_marketing bound to the orders exchange of type fanout . As result, any message sent to orders exchange just copied to orders_processing and orders_marketing exchanges (the feature of the fanoutexchange type).
And you can see that the exchanges orders_processing and orders_marketinghave a type of x-consistent-hash.
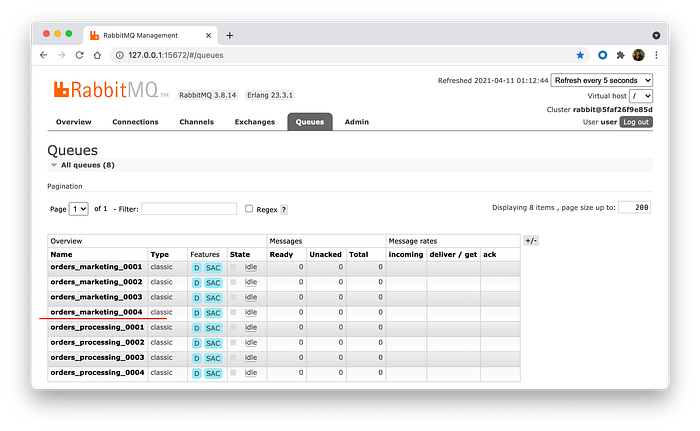
On the queues tab, you can see two sets of queues. They are bound to the corresponding orders_processing and orders_marketing exchanges, and will be processed independently.
Now, let's run the producer from the terminal
export RABBITMQ_CONNECTION_STRING=amqp://user:bitnami@localhost:5672
export WORKING_DIRECTORY=/Users/alexander/git/gorabbit
export TOPIC=orders
producer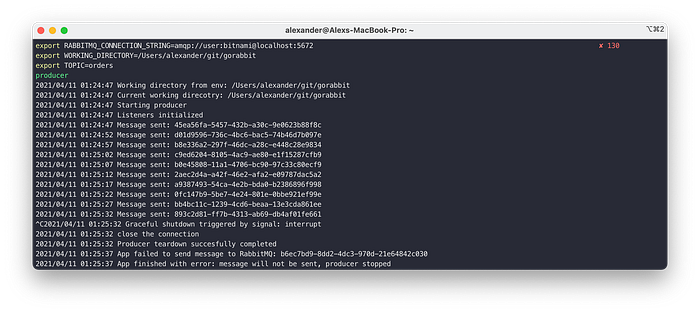
On CTRL+C our producer will trigger an internal graceful shutdown, and exit with the error, cause we still trying to send messages on the stopped producer.
In production, you need to ensure you give your app enough time to finish all its stuff and prevent this situation from happening.
If you run producer before the consumer, and no queues were created, RabbitMQ will send back the messages it failed to route, and the producer will report about it.
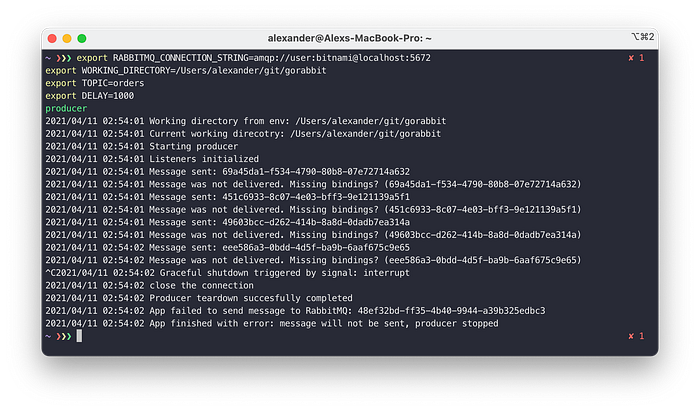
We can check logs and see that our consumers are receiving messages.

And if we play with the producer’s delay settings and allow it to send messages at a high rate to the RabbitMQ, we can see the distribution of the messages over the queues is quite good.
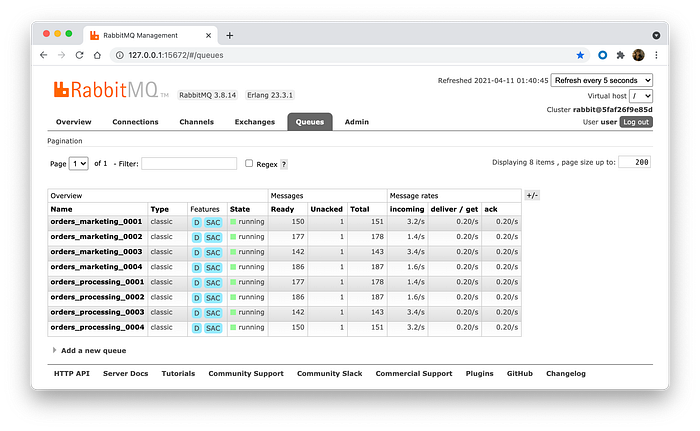
Now, to test our scaling, let change our manifest file to be like that
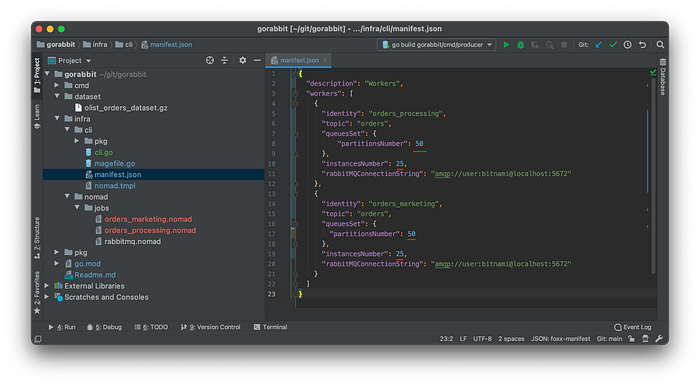
Now let’s run a single command that will generate new mapping, and restart all our consumers.
go run cli.go rescaleOur consumers will receive kill command and do tear-down. It’s your responsibility to stop processing inside the handler. In the source code provided I’m emulating a very heavy message processing, and just decide to stop it in the middle, and let the message back to the queue (by nack command).
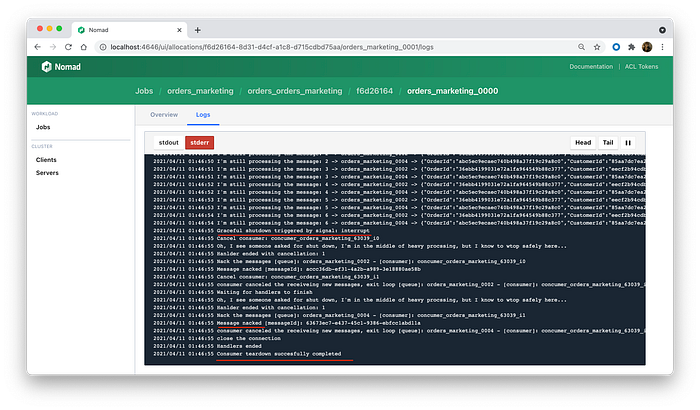
We can check our scaling worked by looking to the RabbitMQ.
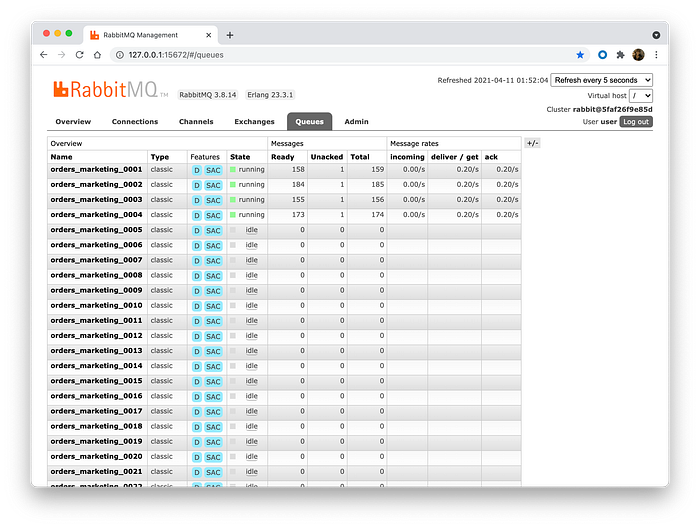
Now, if you rerun our producer, messages will start to go to the new queues as well.

But stop! It means we can lose partial order of the messages because messages with the same routing key can still exist in the old queues.
You are right. And this is exactly the reason the consistent hash algorithm is so useful in our case, in comparison with regular hash algorithms use for load balancing.
Consistent Hashing is a hashing technique whereby each bucket appears at multiple points throughout the hash space, and the bucket selected is the nearest higher (or lower, it doesn’t matter, provided it’s consistent) bucket to the computed hash (and the hash space wraps around). The effect of this is that when a new bucket is added or an existing bucket removed, only a very few hashes change which bucket they are routed to.
For many use cases, this is a very good solution. By keeping queues tail small, and by pre-creating enough amount of queues, these situations should be very rare. You should change the queue amount very rarely.
And finally, to stop our consumers run the command:
go run cli.go shutdownor
go run cli.go SystemShutDownto shut down all the jibs including RabbitMQ.
Source code
Enjoy :)
Disclaimer
The main purpose of the code is to show some ideas on how to use this feature. It's far from being production-ready, has no tests and I’m sure has bugs 😬
I never used this lib in production (I’m using NodeJS on my daily job). Although it quite a mature project, I suggest you go over all the open issues before you decide to use it in production. There are few interesting bugs and surprising behaviors 😉
But hopefully, the lib will be forked by the RabbitMQ team and at least will accept patches for a known issue.
It’s a huge article. If you find any mistakes or bad explanations, please let me know ✌️
